Use cases
Achieve high availability (HA) from the standpoint of Users or Proxies
assuming that:
- the failure of some attempt is temporary or localized to some of the workers
- workers are redundant and interchangeable
- there are enough time and workers
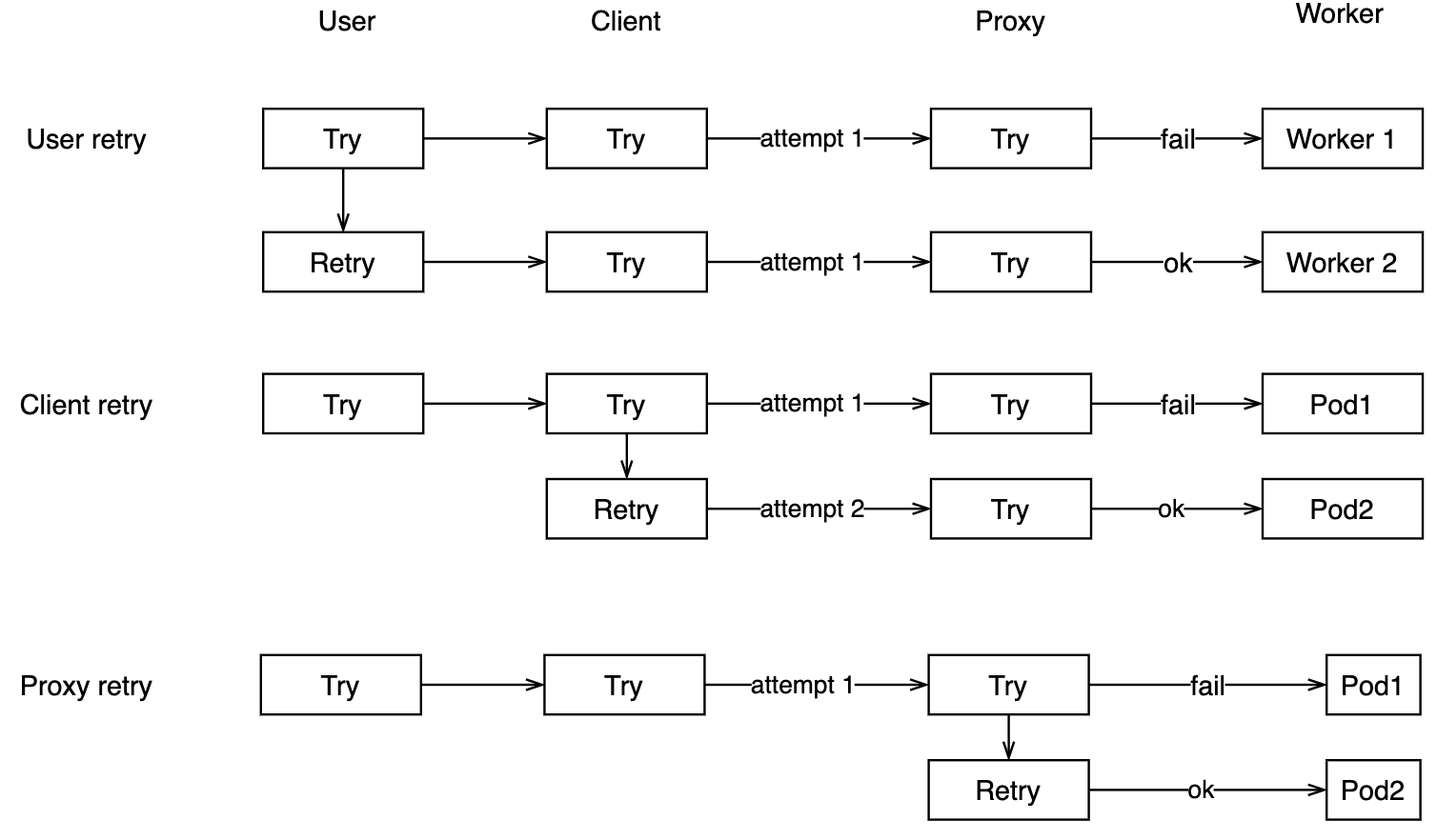
There are several types or levels of retrying:
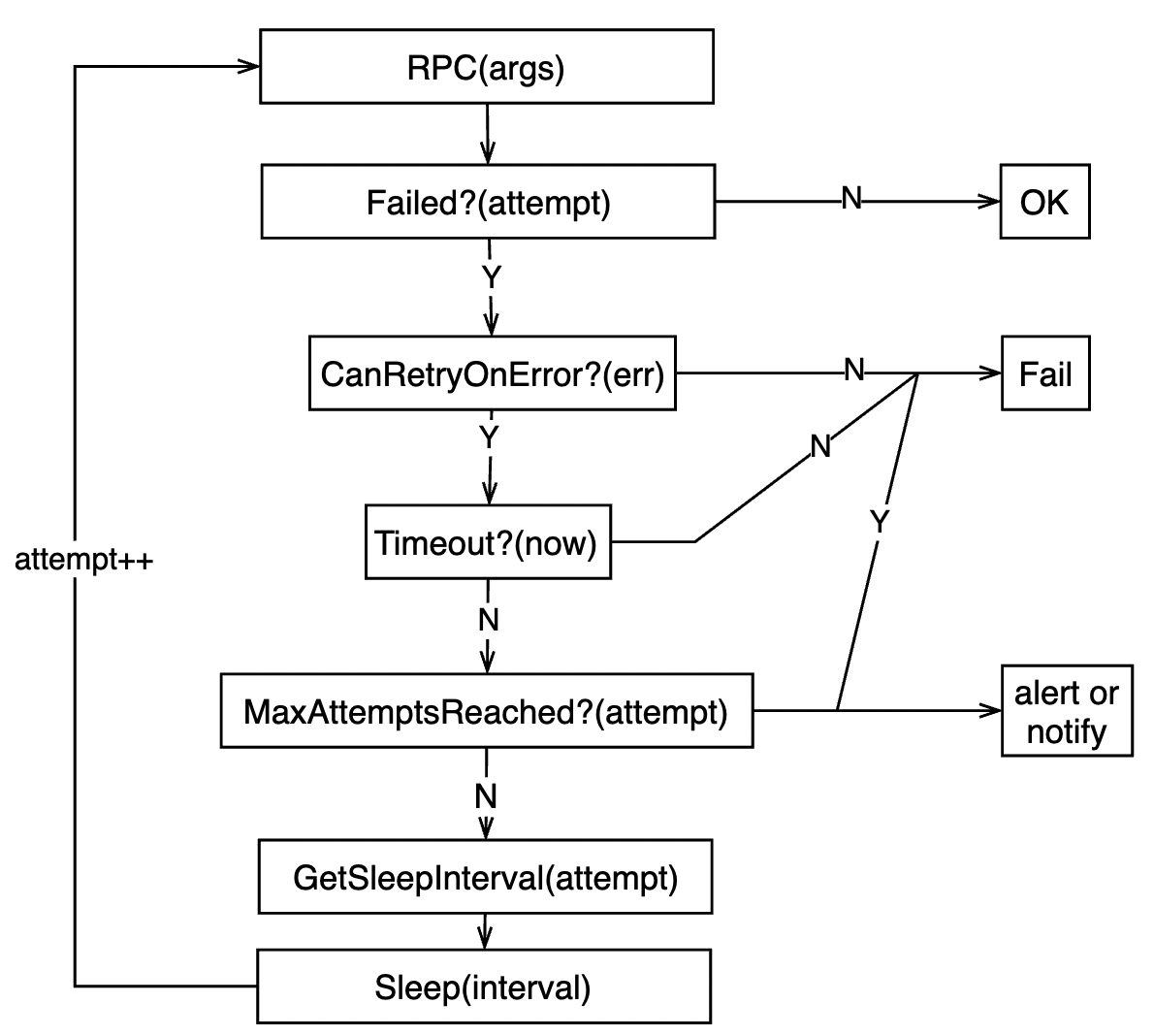
A general control flow of retries:
Polling for a status change without knowing when it’ll happen
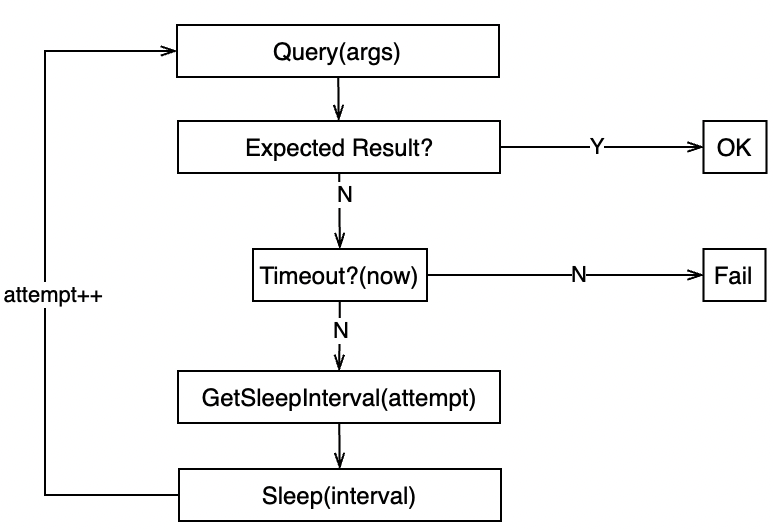
Sleep interval can be linear or exponential, based on your modeling of probability distribution of when the change will happen.
Model
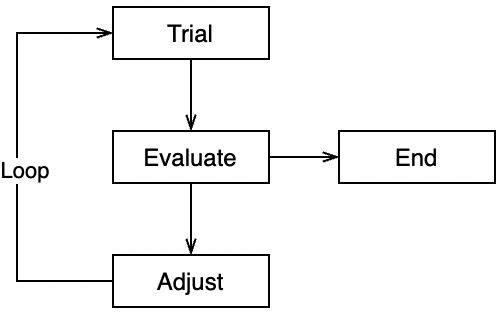
Evaluate by:
- error types (can recover by retrying?)
- number of attempts (max attempts reached?)
- time (timeout?)
The definition of insanity is doing the same thing over and over again, but expecting different results.
– Albert Einstein
Adjust on:
- time (sleep intervals)
- worker (pick another worker / let a load balancer decide)
- request size (response 413 or 429: split large requests into smaller ones)
- request data (User triggered, e.g. fix typo, input correct values)
If the clients are many
client retry strategy becomes a gaming problem, local optimization may cause overall crisis.
- request times (i.e wait intervals) should be randomized to avoid workload peaks
- resource contention and racing condition should be treated by both clients and the service instances
- eliminate unnecessary retries from both client and service side.
Pros and cons for client retries
Pros:
- allows client being resilient to partial / temporary failures
- allows client-driven async workflows (write, polling reads, another write)
Cons:
- may incur side effects (non-idempotent writes cause duplicate data)
- request multiplication is non-linear and positively related to service load and latency (cascading failures)
- may cause racing conditions or hot spots.
To remediate the Cons, we need these technical capabilities on the service side:
- idempotent write APIs
- rate limits / circuit breakers / load balancing with warm-ups
- locks, queues and sharding
Anti-patterns ( “Don’t"s )
Don’t retry on all errors
retry should be based on coded type of errors
http status code:
- 429 too many requests
- 503 service unavailable
see the code in aws sdk retryer
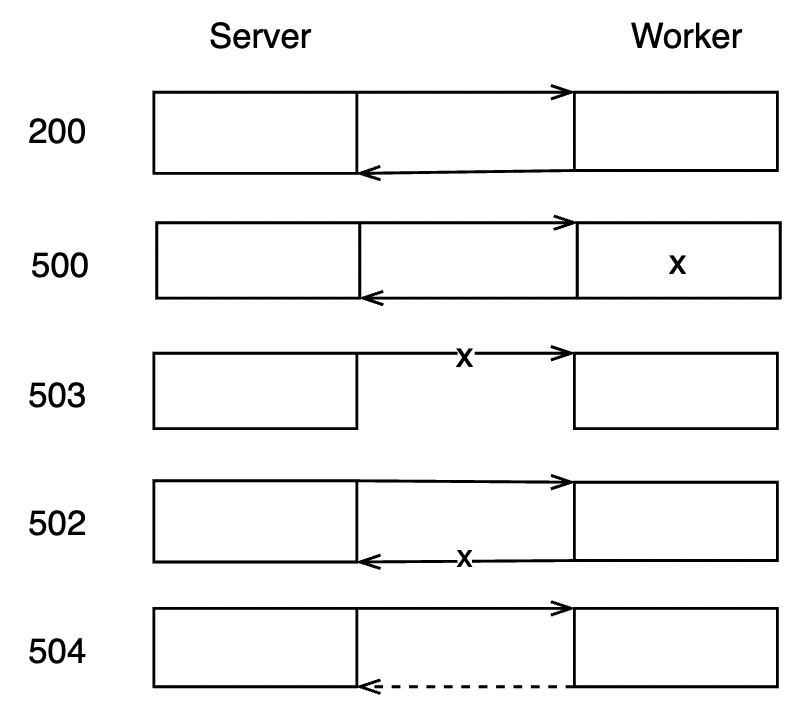
GRPC status code:
- Unavailable
- ResourceExhausted
see the code in go-grpc retryer
Don’t retry instantly
should wait with backoffs, especially when throttled
see the code in aws sdk retryer
Retry-After in seconds:
[0.045, 0.06, 0.09, 0.15, 0.27, 0.51, 0.99, 1.95, 3.87, 7.71, 15.39, 30.75, 61.47, 122.91, 122.91, 122.91, 122.91, 122.91, 122.91, 122.91, 122.91, 122.91, 122.91, 122.91, 122.91]
Don’t retry on the fragile parts
e.g. retry on Services, not on Pods; retry on domain names, not on ips
Don’t retry indefinitely
when maximal time or attempts are exceeded:
- trigger alarms
- manually ignore
- put to dead letter queue for later processing
Guidelines (“Do"s)
- retry on selected errors at the right level (user vs. client vs. proxy vs. worker)
- service should fail fast and explicit (allow downstream to decide should / how to retry)
- pass timeouts through context
- configurable retry parameters (max attempts, per-attempt timeout, retry-able error codes)
- apply back-pressure (TCP flow control, 429 responses, alarm triggering scaling and throttling actions)
- idempotent writes (avoid duplicate data)
Cascading failures, the nightmare of system operators (SREs)
positive feedback loop
Case 1. DynamoDB OOS because GSI was introduced in 2015
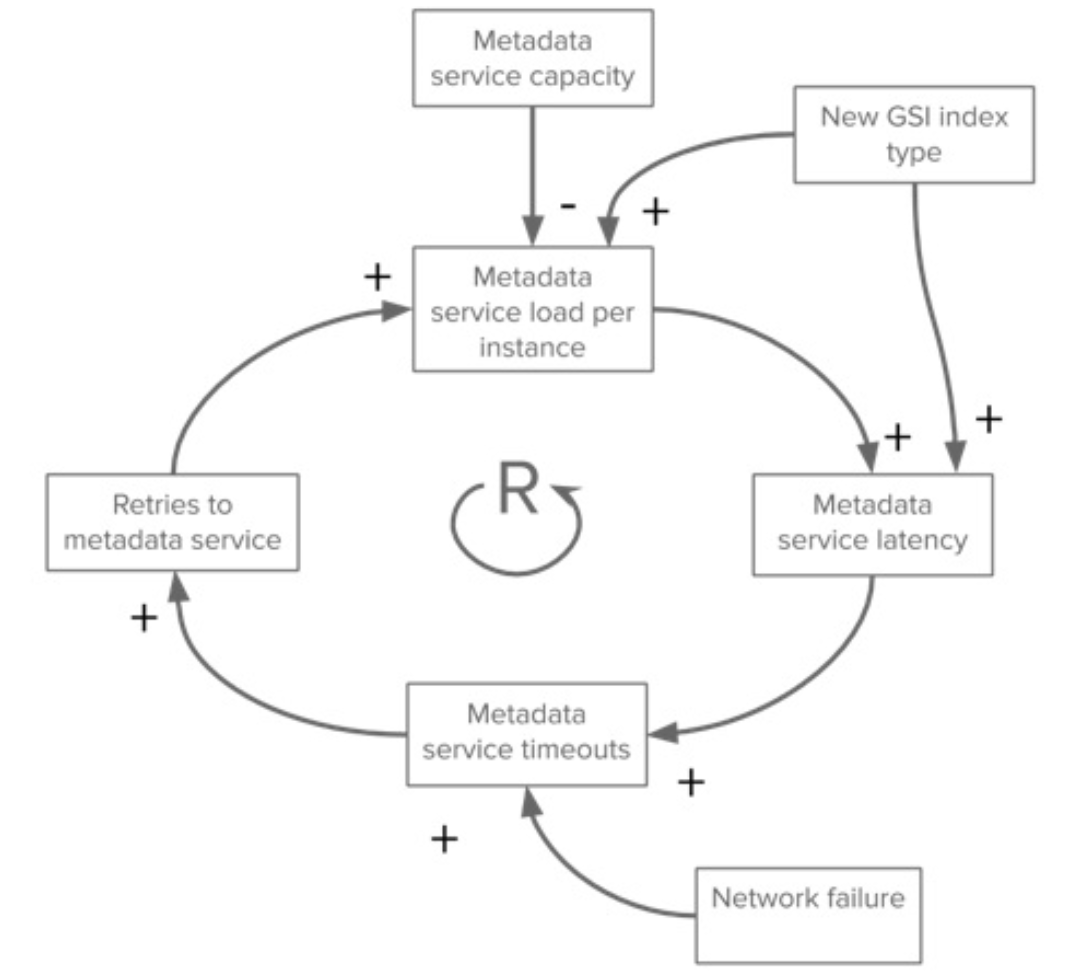
https://aws.amazon.com/message/5467D2/
https://www.infoq.com/articles/anatomy-cascading-failure/
If service capacity is not added quickly enough and the load balancing is naive (round-robin or least-conn), new capacities will be flooded quickly (domino effect)
Lessons learned:
- avoid resource contention between client-facing requests and administrative ones
- sharding on metadata
- reduce retries to a lower rate
Case 2. AWS us-east-1 down because Kinesis frontend fleet scaling out limitations
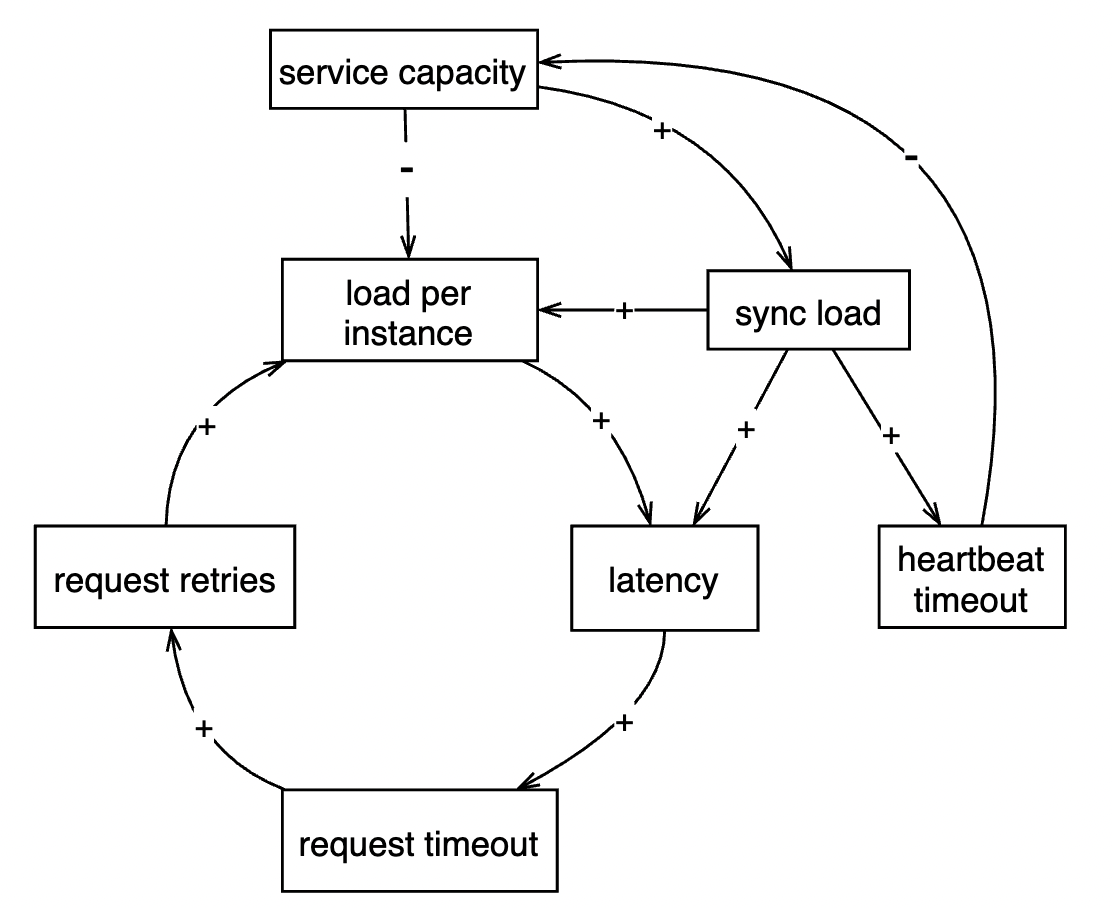
https://aws.amazon.com/message/11201/
the issue was identified within 4 hours, but the recovery process (manually restarting servers in batches and ramping up workload) took over 17 hours.
because if service capacity is added too quickly, there are significant resource contentions causing the new capacities to be unhealthy and taken down.
Lessons learned:
- horizontal scaling may have unknown limits (open file handlers, thread counts, network bandwidth etc) that sometimes vertical scaling is required
- avoid resource contention on administrative and client-facing workloads
- avoid n-to-n synchronizations
- sharding on fleets