Disclaimer: this is the manuscript of a chapter in a published technical book: Cloud-Native Application Architecture: Microservice Development Best Practice which is co-authored by several of my ex-colleagues at FreeWheel.
As software systems move from monolithic applications to microservices and cloud-native services, and with the trend of decentralized and heterogeneous database selection, can ACID transactions, previously built on monolithic applications and single traditional relational databases, achieve the same functionality on distributed systems and diverse databases? If so, what pitfalls and considerations are essential in the transitional mindset? This chapter will introduce our team’s experience and practice pertaining to the technical topic of distributed transactions.
Theoretical Foundations
This section introduces the background of distributed transactions and related concepts, including ACID, CAP, BASE, etc., starting from the perspective of architecture and business changes.
Background
As the business and architecture are constantly changing, software systems tend to fall into a seemingly inevitable situation, where the business model and the data storage model cannot be aligned. This is the reason why transactions came into being. While traditional ACID transactions were widely studied and commonly used in the era of monolithic applications, distributed transactions are an increasingly prominent engineering problem in the context of microservices.
Business changes
Software systems, in order to achieve certain business functions, will abstractly represent people, things and objects in the real world and map them into models in software systems. Borrowing ideas from systems theory, a generic business model can be constructed in the following steps.
- Define what entities exist in the system and what attributes are available on the entities. For example, for a trading system, buyers, sellers, orders, and traded goods are all entities, and for the entity of orders, there may be attributes such as transaction time and transaction price.
- Define various topological relationships between entities, such as subordinate, nested, and many-to-many. For example, buyers and sellers are many-to-many relationships, and transacted goods and orders are subordinate to each other.
- Define the dynamic relationships of entities and attributes, which are the processes of the system. In order to record and track changes in the system and make the system’s behavior easy to understand and review, the process is usually abstracted as changes in several key attributes on a set of entities; these changes can be subdivided into states (the values of key attributes, usually finite and discrete values), transfers (which states can change to which states), and conditions (what constraints are satisfied to achieve the transfer of states). For example, a transaction in the system from placing an order to confirming receipt is a process that is driven by a change in the state of the order as an entity, and the state transfer of the order needs to satisfy some conditions, such as sufficient inventory.
The first two steps can be captured by drawing the entity-relationship diagram of the system, which represents all possible states of the system at any one time point. The third step can be expressed by a flowchart and a state-transfer diagram, which represent the system’s change pattern over time (or sequence of events).
In particular, when designing the state-transfer diagram of a system, it usually demands that the values of state are mutually-exclusive and collectively-inclusive, i.e., the system is in a given state at any point in time, and cannot be in two states at the same time. Only then can the state-transfer diagram completely and correctly characterize all possible states and change patterns of the system.
But as stated in the previous sections, the single contant in a system is the change itself, and the business model is usually the most change-prone part. Corresponding to the steps of business modeling, changes in the business model are usually reflected in:
- Increase or decrease in the types of entities and attributes in the system, such as the subdivision of the buyer entity into individuals and merchants, and the addition of attributes such as billing method and shipping address to the order entity.
- Changes in entity topology, such as orders can be split into sub-orders and packaged orders.
- Process changes, such as the need to add the step of locking inventory before placing an order.
In addition, even if the entities and relationships in the system remain the same, the number of certain types of entities and relationships may change, such as the number of tradable items suddenly increasing to 100 times the original number, or the number of new orders added daily suddenly increasing to 10 times the original number.
Architectural changes
Although the business value of software systems lies in the ability to achieve certain functions, the prerequisite of completing these functions is to meet some basic requirements unrelated to the specific business, such as stability, scalability, parallel development efficiency, energy-utility ratio, and so on. Along with the surge in data volume and functional complexity, the technical architecture and engineering methodology supporting R&D are evolving and innovating.
Software systems follow the computation-storage architecture proposed by computer science pioneer John von Neumann, which stands that most of the components are stateless or volatile computational units, and only a few components are responsible for “persisting” data onto a disk. The components responsible for storing these components are the database, and the other computational components that read and write data can be regarded as the clients of the database. The design of the data storage model is basically equivalent to the database design, which includes data storage structure, index structure, read and write control, etc.
In the traditional monolithic application era, software systems usually use a single relational database (RDBMS): a software system corresponds to a database, an entity corresponds to a table, the attributes on the entity corresponds to the fields in the table, usually to ensure the consistency of the business model data, but also to minimize redundant storage tables and fields, forming the so-called database design paradigm.
In the context of microservices, the entire software system is no longer limited to using a single database, in order to meet the needs of diverse indexing and query data, each service can even choose to use a number of special databases specializing in certain areas, such as Apache Solr and ElasticSearch as the representative of the search engine (Search Engine), and such as The database can be distributed to access large amounts of data, such as Amazon DynamoDB and MongoDB, which are NoSQL document databases.
transactions
On the one hand, business changes drive the iterative business model, which inevitably leads to changes in the data storage model to some extent, that is, the addition and deletion of database tables, fields, indexes and constraints, as well as changes in the mapping relationship from the business model to the storage model; on the other hand, non-functional requirements continue to drive the evolution of technical architecture and engineering methodology On the other hand, non-functional requirements continue to drive the evolution of technical architectures and engineering methodologies, making database selection more diverse and decentralized.
In order to accommodate these two changes, it seems unavoidable that the state of the business model and the state of the storage model diverge and do not correspond one-to-one in the process of continuous service boundary adjustment. For example, after a buyer makes a payment, a series of changes need to be completed such as deduction of product inventory, increase or decrease of buyer and seller account balances, modification of order status to paid, etc. That is, the transfer of the business model from the state of pending payment to the state of paid needs to correspond to the joint changes of multiple fields on the inventory table, order table and even more related tables. For example, in order to improve the conversion rate of users from browsing to purchasing, the previous multi-step order placement process is changed to one-step creation, which is equivalent to the reduction and merging of the number of states on the business model, while the data storage model must be adjusted accordingly.
In order to ensure the mutually exclusive completeness of the state on the business model, the software system inevitably requires that the state of the storage model is also mutually exclusive: from the perspective of the database, some fields on some tables in the database must change at the same time; and from the perspective of the database client, a set of write operations to the database either take effect or they do not. This constraint is actually a transaction.
ACID: Transaction Constraints in the Traditional Sense
In a traditional relational database, a set of data operations that succeed and fail at the same time is called a transaction, and consists of four aspects, abbreviated as ACID.
- A (Atomicity, Atomicity): a set of data operations if one of the steps of the operation fails, the previous operations should also be rolled back, not allowing the case of partial success and partial failure.
- C (Consistency, consistency): data operations conform to some business constraints. This concept comes from the field of financial reconciliation, and the meaning of expanding to database design is rather vague, and there are many different opinions. Some sources even say that C is added to make up the acronym ACID.
- I (Isolation): There is a certain amount of isolation for concurrent data operations. The worst case is that concurrent operations are not isolated from each other and interfere with each other; the best case is that concurrent operations are equivalent to a series of serial operations (Serializable). The higher the isolation level, the more resources the database needs, and the worse the performance of accessing data (e.g., throughput, latency).
- D (Durability): Requests arriving at the database will not be “easily” lost. Usually database design documents will define “easily” specifically, for example, not losing data during disk bad physical sectors, machine power outages and restarts.
CAP: The Challenge of Distributed Systems
As the topology of software systems moves from monolithic applications into the era of microservices and the number and variety of databases grows, distributed systems, especially databases, face greater challenges than monolithic applications and traditional relational databases in meeting the transactional requirements of traditional ACID standards.
The so-called CAP triple-choice theorem states that no distributed system can satisfy all three of the following properties at the same time.
- C (Consistency, strong consistency): any node of the distributed system for the same key read and write requests, the results obtained exactly the same. Also called linear consistency.
- A (Availability): Each request gets a timely and normal response, but there is no guarantee that the data is up-to-date.
- P (Partition tolerance): The distributed system can maintain operation if the nodes cannot connect to each other or if the connection times out.
Among the three characteristics of CAP, tolerating network separation is usually a given fact that cannot be avoided: if there is no network separation in the system, or if the system is not required to work properly in case of network separation, then there is no need to adopt a distributed architecture at all, and a centralized architecture is simpler and more efficient. With the acceptance of P, the designer can only make a trade-off between C and A. Few distributed systems insist on C.
Few distributed systems insist on C and abandon A, i.e., choose strong consistency and low availability. In such systems, a request to write data returns a response only after it has been submitted and synchronized to all database nodes, and a failure of any node or network separation will result in the service being unavailable as a whole until the node failure is recovered and the network is connected. The service availability depends on the frequency of failure and recovery time. This choice is usually made for systems involved in the financial sector, even without a distributed architecture.
Most systems, on balance, choose A and reduce the requirements for C, with the goal of high availability and eventual consistency. In such systems, a request to write data returns a response as soon as it is successfully submitted on some of the database nodes, without waiting for the data to be synchronized to all nodes. The advantage of this is that the availability of the service is greatly increased, and the system is available at any time as long as a few nodes are alive. The disadvantage is that there is a certain probability that the result of reading the same data will be wrong for a period of time (unknown length and no upper limit) after the write data request is completed. This data constraint is called BASE.
BASE: The Cost of High Availability
BASE is a weaker transactional constraint than ACID in distributed systems, and its full name is Basically Available, Soft state, Eventually consistent (eventually consistent). Here is a look at the meaning of each of these terms.
- Basic Availability: By using a distributed database, read and write operations are kept in as usable a state as possible, but data consistency is not guaranteed. For example, a write operation may not be persistent, or a read operation may not return the most recently written value.
- “Soft” state: The state of a piece of data is unknown for some time after it is written, and there is only a certain probability that the system will return the latest written value before it finally converges.
- Eventually consistent: Under the premise that the system functions normally, after waiting long enough, the state of a piece of data in the system can converge to a consistent state, after which all read operations on it will return the latest written value.
BASE is a detailed representation of the decision to choose high availability and relax data consistency in the design of distributed systems. It discusses the state changes that occur in a data system after a data is written: the state of the data on multiple slices goes from consistent to inconsistent to consistent, and the value returned by a read operation goes from stable to the correct old value, to unstable to both old and new values, to stable to the new value.
It should be noted that BASE mainly discusses the behavior of a data read and write operations in a data system, another situation often occurs in practical applications, that is, a data stored in multiple data systems. Let’s look at an example of data consistency across multiple data systems.
Write order
A distributed system with a distributed or even heterogeneous data storage scheme may have data inconsistencies caused by concurrent write order differences on different services/databases for the same piece of data. For example, there are three services A, B and C, each using a different database, and now there are two requests 1 and 2, concurrently modifying the same data item X. Different fields of X are processed by A, B and C respectively. Due to random network delays, X ends up landing in the three services/databases with inconsistent values, A with a value of 2 and B and C with a value of 1. As shown in the figure.
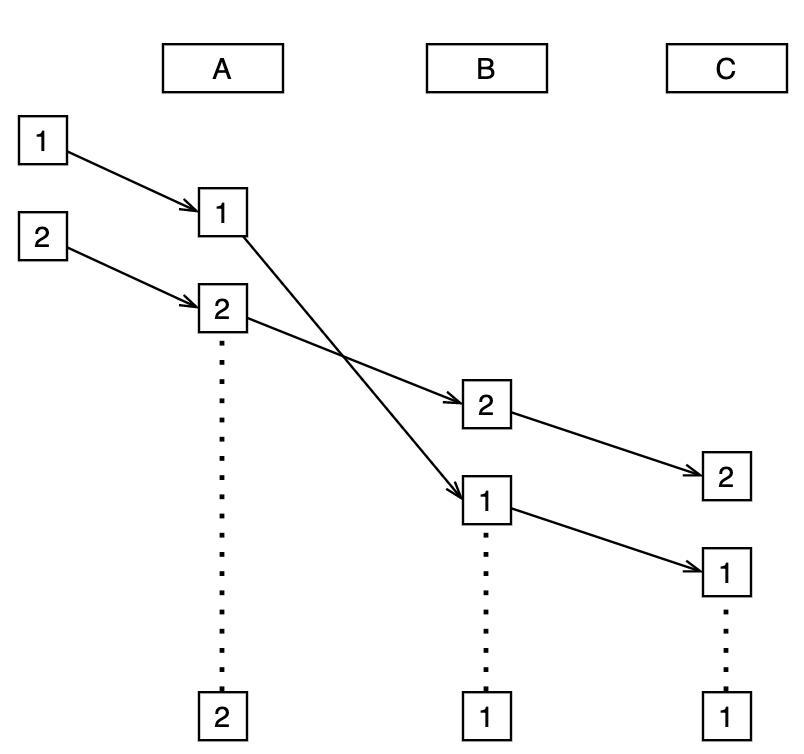
This multi-database write data order inconsistency problem does not necessarily violate the BASE or ACID constraints, but the system is also in an unintended state from a business model perspective.
Solution Selection for Distributed Transaction Framework
Based on the background of distributed transactions and related concepts, this section will discuss some topics of distributed transaction solution selection. First, we will introduce some relevant practices in academia and industry, and then we will introduce a distributed transaction solution developed by the FreeWheel core business team, including its design goals, technical decisions, overall architecture and business processes, etc.
Existing Research and Practice
As a technical challenge and a business necessity, there are a lot of research and practice on distributed transactions in both academia and industry, listed below, to name a few.
XA standard and two-phase commit protocol
The XA standard is an abbreviation for eXtended Architecture (the extended architecture here is actually ACID transactions), which is led by The Open Group to try to provide a set of standards for distributed transaction processing. XA describes the interface between the global transaction manager and the local resource manager. Through this interface, applications can access multiple resources (e.g., databases, application servers, message queues, etc.) across multiple services within the same transaction that maintains ACID constraints. XA uses the Two-phase Commit (abbreviated as 2PC) protocol to ensure that all resources commit or roll back any particular transaction at the same time.
The two-phase commit protocol introduces the role of an orchestrator, which is responsible for unifying the results of operations across data storage nodes (called participants). In the first phase, participants perform data operations concurrently and notify the coordinator of their success; in the second phase, the coordinator decides whether to confirm the commit or abort the operation based on feedback from all participants, and communicates this decision to all participants.
The advantages of using XA and two-phase commit to implement distributed transactions are:
- Strong consistency: ACID constraints on data across multiple databases are achieved.
- Less business intrusive: Distributed transactions rely entirely on the support of the individual databases themselves and do not require changes to the business logic.
The disadvantages of using XA to implement distributed transactions are also obvious:
- Database selection restrictions: The database selection for the service introduces the restriction of supporting the XA protocol.
- Low availability and network fault tolerance: The coordinator or any one of the participants is a single point of failure, and no network separation can occur between any components.
- Low performance: Databases that support XA features are designed with a large number of blocking and resource-occupying operations, and have poor data volume and throughput scalability.
XA is designed to be a strongly consistent, low-availability design solution that does not tolerate network separation, and although it meets the constraints of ACID transactions, its practice in industry is quite limited and usually confined to the traditional financial industry.
Saga
Saga originally means a long mythical story. It implements distributed transactions with the help of a driven process mechanism that executes each data operation step sequentially and, in case of failure, performs the “compensating” operations corresponding to the previous steps in reverse order. This requires that the services involved in each step provide a compensating operation interface that corresponds to the forward operation interface.
The advantages of using Saga to implement distributed transactions are:
- Microservices architecture: A number of underlying services are combined/organized to fulfill various business requirements.
- High database compatibility: there is no requirement for each service to use any database technology, and the service can even be database free.
The disadvantages of using Saga to implement distributed transactions are:
- Requires the service to provide a compensating interface: increases the cost of development and maintenance.
- Not ACID compliant: Isolation (I) and durability (D) are not addressed.
Saga can also be divided, process-wise, into two variants: Orchestration (symphony) and Choreography (dance in unison).
- Saga Orchestration
Saga Orchestration introduces a role similar to that of the coordinator in XA to drive the entire process.
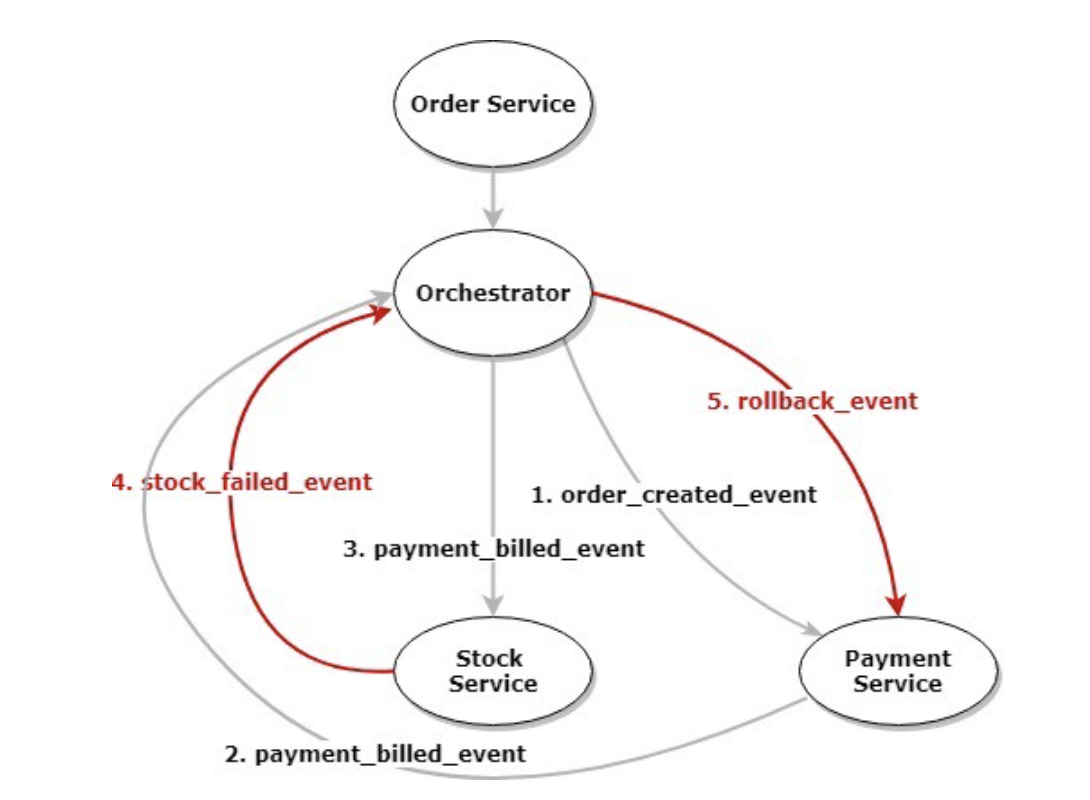
As shown in the diagram, Order Service initiates the distributed transactions, Orchestrator drives the distributed transaction process, and Payment Service and Stock Service provide the forward and compensation interfaces for data manipulation.
- Saga Choreography
Saga Choreography, on the other hand, splits the process into the services involved in each step, with each service calling the back-order or front-order service itself.
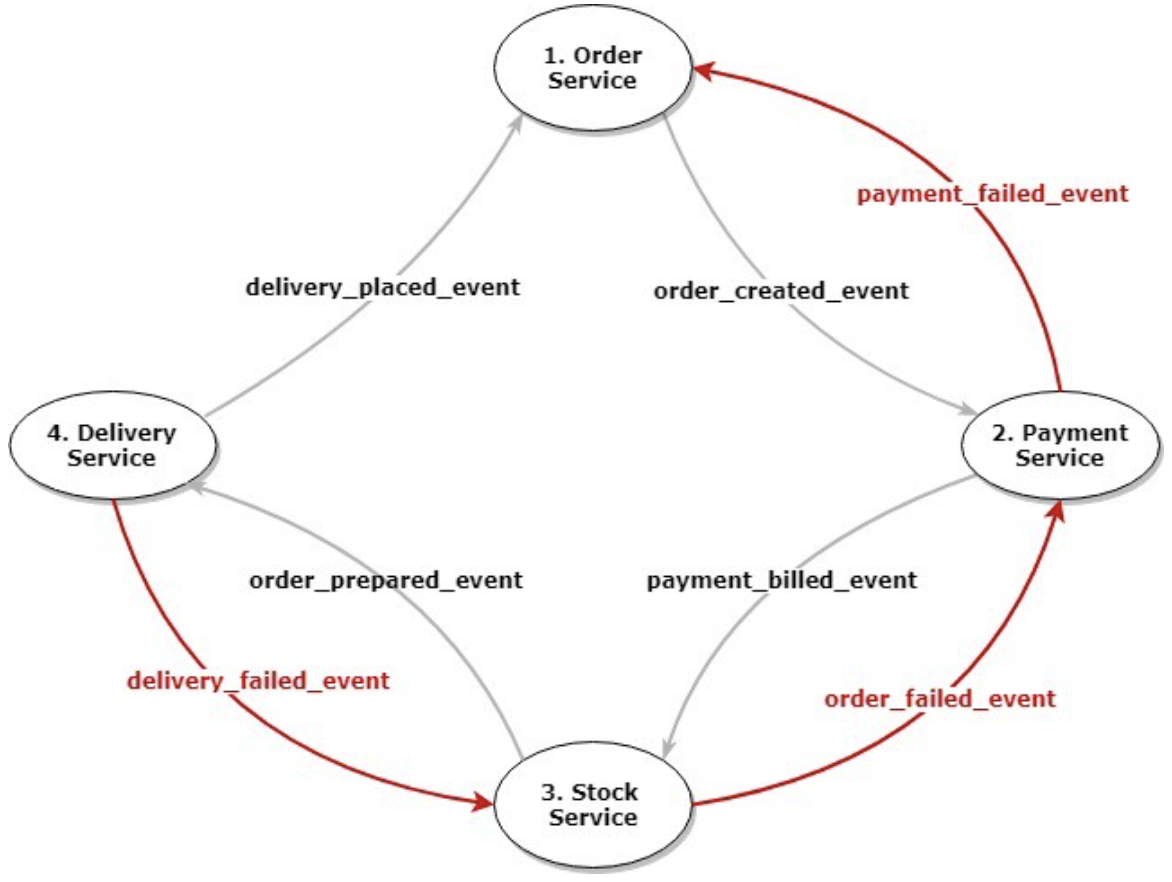
As shown in the diagram, the Order Service directly calls the Payment Service to initiate a distributed transaction, which in turn calls the Stock Service until all steps are completed; if a step fails, the call is reversed between the services.
ACID Transaction Chains
ACID transaction chaining can be seen as a Saga Choreography enhancement that requires all services involved in a distributed transaction to use a database that supports traditional ACID transactions, and within each service, packages data operations and synchronous invocations of neighboring services into an ACID transaction, enabling distributed transactions through chained invocations of ACID transactions.
The advantages of using ACID transaction chaining to implement distributed transactions are:
- ACID-compliant: Each step is a traditional ACID transaction, and the whole is ACID-transactional.
- No need for a service to provide a compensation interface: rollback operations are performed by a database that supports ACID transactions.
The disadvantages of using ACID transaction chains for distributed transactions are:
- Database selection restrictions: The database selection for the service introduces the restriction of supporting traditional ACID transactions.
- Too much service coupling: the dependency between services is a chain topology, which is not convenient to adjust the order of steps; as the number of various business processes using distributed transactions increases, it is easy to generate circular dependencies between services, causing difficulties for deployment.
Design goals of distributed transaction framework
After investigating the above industry practices, the FreeWheel core business system decided to pursue developing a distributed transaction solution, in order to achieve the following design goals:
- The business can define a set of data operations, i.e. distributed transactions, which either succeed or fail at the same time, regardless of the service and database in which they occur. Whenever any operation in the transaction fails, all previous operations need to be rolled back.
- Overall high availability of the system: When some nodes of some services fail, the system as a whole is still available. By supporting the rapid expansion and shrinkage of services to achieve high throughput of the system as a whole, as short as possible to achieve consistency of data latency. The framework itself consumes low resources and introduces little latency overhead.
- Data eventual consistency: concurrent operation of the same data requests arrive at each service and database in the same order, without the previously mentioned inconsistent write order phenomenon.
- Support for service-independent evolution and deployment: There are no requirements or assumptions about how services are implemented, except for support for communication using RPC and a given protocol.
- Support services to use heterogeneous data storage technologies: Using different data storage technologies (relational databases, NoSQL, search engines, etc.) is the status and effort of each service of FreeWheel’s core business system.
- The architecture is less invasive and easy to adopt: no or less changes are made to the code and deployment of the existing system, and as much as possible, the operating environment and specific business processes of distributed transactions are implemented only by adding new code as well as service deployment. Clear division of labor between framework and business, maintaining 100% test coverage for framework code, 100% testability for business code, and low testing costs. Maintain high visibility and predictability of the system, as far as possible to facilitate rapid fault location and recovery.
- Support for synchronous and asynchronous processes: provide a mechanism to bridge the synchronous interaction process between the UI/API and the back-end entry service, with the possible asynchronous process between the back-end services.
- Support for transaction step dependencies: whether and how data operations at a step inside a transaction are executed depends on the results of the operations of the preceding steps.
Choosing Saga
We first rule out the XA solution, which does not meet the high availability and scalability of the system. Secondly, we ruled out the ACID transaction chain because it is not compatible with the existing database selection of the business, and more database technologies that do not support ACID transactions will be introduced in the future.
The final decision to use Saga to implement a highly available, low-latency, and eventually consistent distributed transaction framework was based on the fact that its design ideology fits well with the current SOA/microservices/Serverless practice of the FreeWheel core business team, i.e., by combining/orchestrating some basic services (actually Lambda for Serverless, not to be distinguished here) to The combination/orchestration of some basic services (actually Lambda for Serverless) to fulfill various business requirements.
After comparing the two variants of Saga, we chose Orchestration over Choreography for the following reasons:
- Service decoupling: Orchestration naturally decouples the driver logic of the transaction itself from the many underlying services, while Choreography is prone to circular dependency problems between services without introducing queues.
- Service layering: Orchestration naturally separates services into two invocation levels, the combination/orchestrator and the domain service, which facilitates the extension and reuse of business logic.
- Data decoupling: For business scenarios where a step depends on the results of multiple steps in the previous order, the latter requires all services in the previous order to pass through data from other services, which Orchestration does not.
By adopting Saga Orchestration, two of its drawbacks must be overcome, namely, the requirement for the underlying service to provide a compensation interface and the lack of implementation of the isolation and durability constraints in ACID.
Implementing data compensation operations
Data operations can be divided into Insert (New), Delete (Delete) and Update (Update) three, and Update can be subdivided into Full update (Replace, overall update) and Partial update (Patch, partial update), they correspond to the following compensation operations.
- Insert: The compensation operation is Delete, the parameter is the ID of the data, and the ID of the data is required to be recorded after the Insert operation.
- Delete: The compensating operation is Insert with the parameter of complete data, which requires the current complete data to be recorded before the Delete operation is performed.
- Full update: The compensating operation is another Full update with the parameter Full data, which requires the current full data to be written down before the original Full update operation.
- Partial update: The compensation operation is a Partial / Full update with the parameter Partial or Full data before the change, which requires the current partial or full data to be written down before the original Partial update operation.
Implementing Isolation and Durability Constraints in ACID
Isolation is really a question of how to control concurrency, i.e. how to handle concurrent operations on the same data (same key). MySQL, as one of the mature relational databases, has introduced the Multiple Version Concurrency Control (MVCC) mechanism. The main idea to control concurrency without introducing multiple versions is to remove concurrency and turn it into a string, which has two main types of implementations: preemptive locks or using queues. Considering the performance loss due to waiting for locks and the possibility of interlocking due to inconsistent order of multiple locks, we prioritize the use of queues to remove concurrency.
Durability means that a transaction successfully committed to the system cannot be lost in the middle, i.e., data persistence is achieved. The failures to be considered include the failure of data storage nodes and the failure of data processing nodes.
In summary, in order to comply with the ACID constraint, a queue + persistence technology solution is needed to complement the two shortcomings of Saga. Combined with the existing infrastructure mapping of FreeWheel’s core business system, we prioritized the introduction of Apache Kafka (hereinafter referred to as Kafka).
Introducing Kafka
Kafka is queue plus persistence solution with rich features designed for distributed systems, including the following capabilities:
- Message Preservation: Introducing queues to turn concurrent writes into strings and solve the isolation problem of concurrent writes.
- Message Delivery Guarantee: Supports “at least once” message delivery guarantee, with redundant backup and failure recovery capabilities, which helps solve the ACID durability problem.
- Excellent performance: Various sources show that Kafka itself is the industry benchmark for efficiency and reliability, and if used properly, it will not become a performance bottleneck for the system.
On the other hand, as a powerful queuing solution, Kafka bring new challenges to the design and implementation of distributed transactions.
For example, before the introduction of queues, the nodes in the main process were interacting synchronously from the time the customer clicked the browser button to the time the data was dropped and the response data was returned; after the introduction of queues, the producers and consumers at the two ends of the queue are separated from each other, and the whole process switches from synchronous to asynchronous and back to synchronous again, as shown in the figure, where the solid arrows are RPC requests and the dashed arrows are RPC responses, and the data is processed in the order of the steps marked by the serial number The data is initiated from the client in the order of the steps marked by the serial number, and passes through services A, B and C.
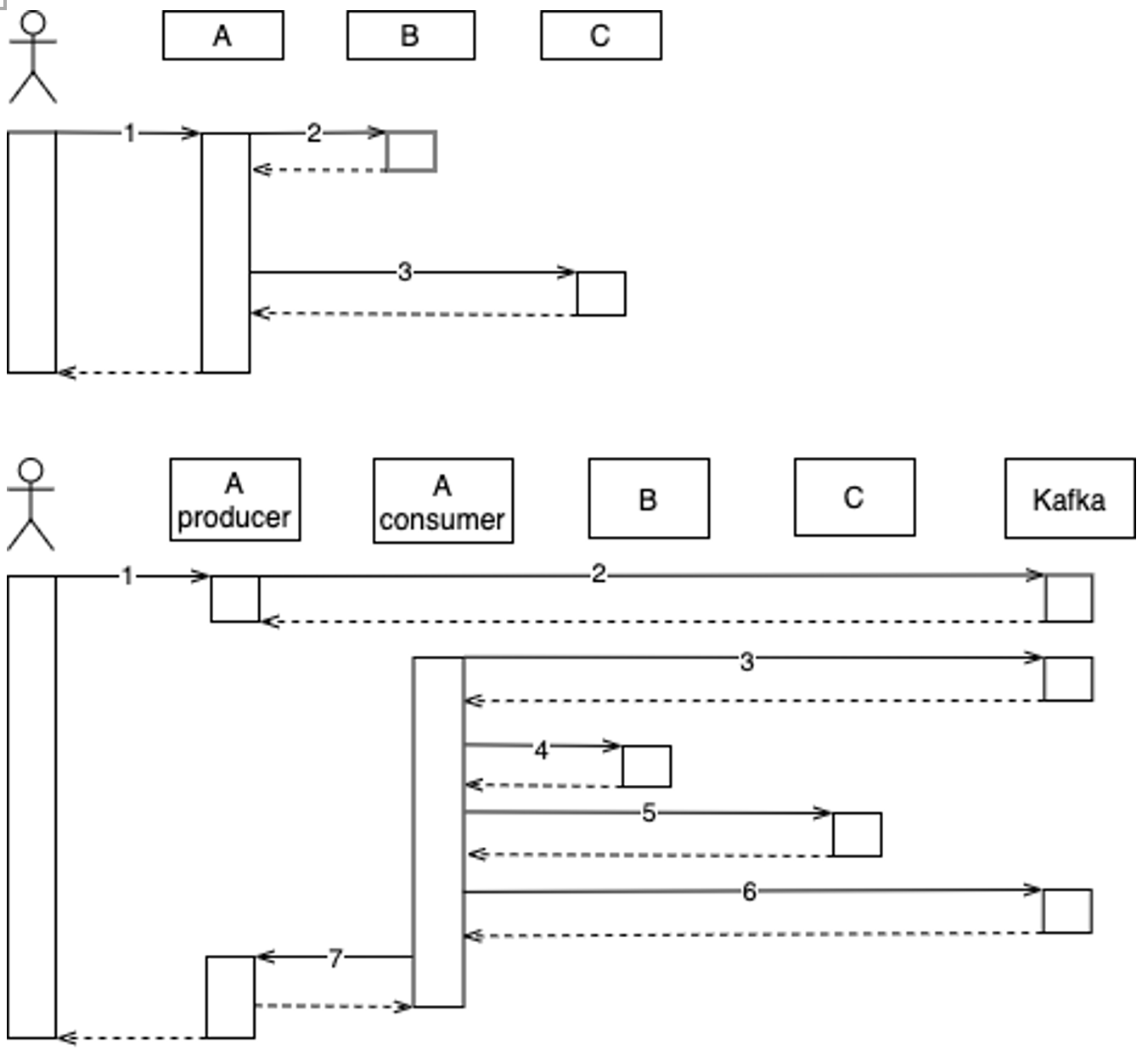
As you can see, before the introduction of the queue, all steps are executed in synchronous order; after the introduction of the queue, Step 1 and 2 are synchronous, 2 and 3 are asynchronous, and the next steps 3 through 7 are synchronous again.
Although the overall throughput and resource utilization of the system can be further improved by turning synchronous into asynchronous, the design of how to connect synchronous and asynchronous processes needs to be added in order to maintain the synchronous front-end data process.
Synchronous-asynchronous conversion mechanism design
Synchronous to asynchronous conversion is relatively simple and can be achieved by sending messages to Kafka asynchronously through the Goroutine in Go or the thread mechanism in Java, etc., which is not discussed here.
Asynchronous to synchronous is a bit more complicated and requires a mechanism for peer-to-peer communication between the node where the consumer is located and the node where the producer is located. One approach is to introduce another Kafka queue, where the consumer finishes processing a message, encapsulates the result in another message, and sends it to the queue, while the producer’s process starts a consumer that listens and will process it,
We take a different approach: the producer wraps the callback address into the message, and the consumer sends the result to the callback address after processing is complete. This works because in our existing deployment scenario, the networks of the nodes where the producer and consumer are located are interoperable.
Queue Message Protocol Design
A queued message for a distributed transaction contains at least two parts of information: Metadata and Content. As shown in the figure.
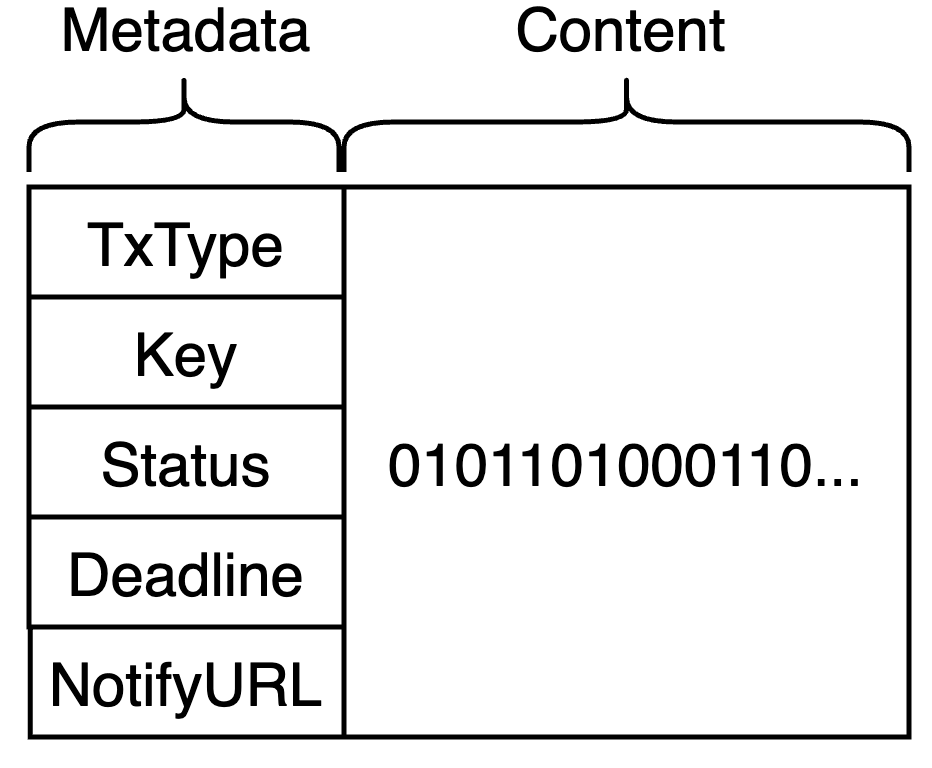
- Metadata: read and written by the distributed transaction framework, using JSON format, field format fixed, business code can only read, not write. The most important field in the metadata is the type of the distributed transaction message (hereafter referred to as TxType). The producer specifies the TxType of the message by the strong type; the distributed transaction framework in the consumer process performs event sourcing based on the TxType and invokes the corresponding business logic for consumption.
- Content: read and write by the business code, the format is arbitrary, the framework does not parse, as long as the length does not exceed the limit of the Kafka topic (default 1MB).
System architecture
The architecture of the distributed transaction system based on Saga Orchestration and Kafka is shown in the following figure.
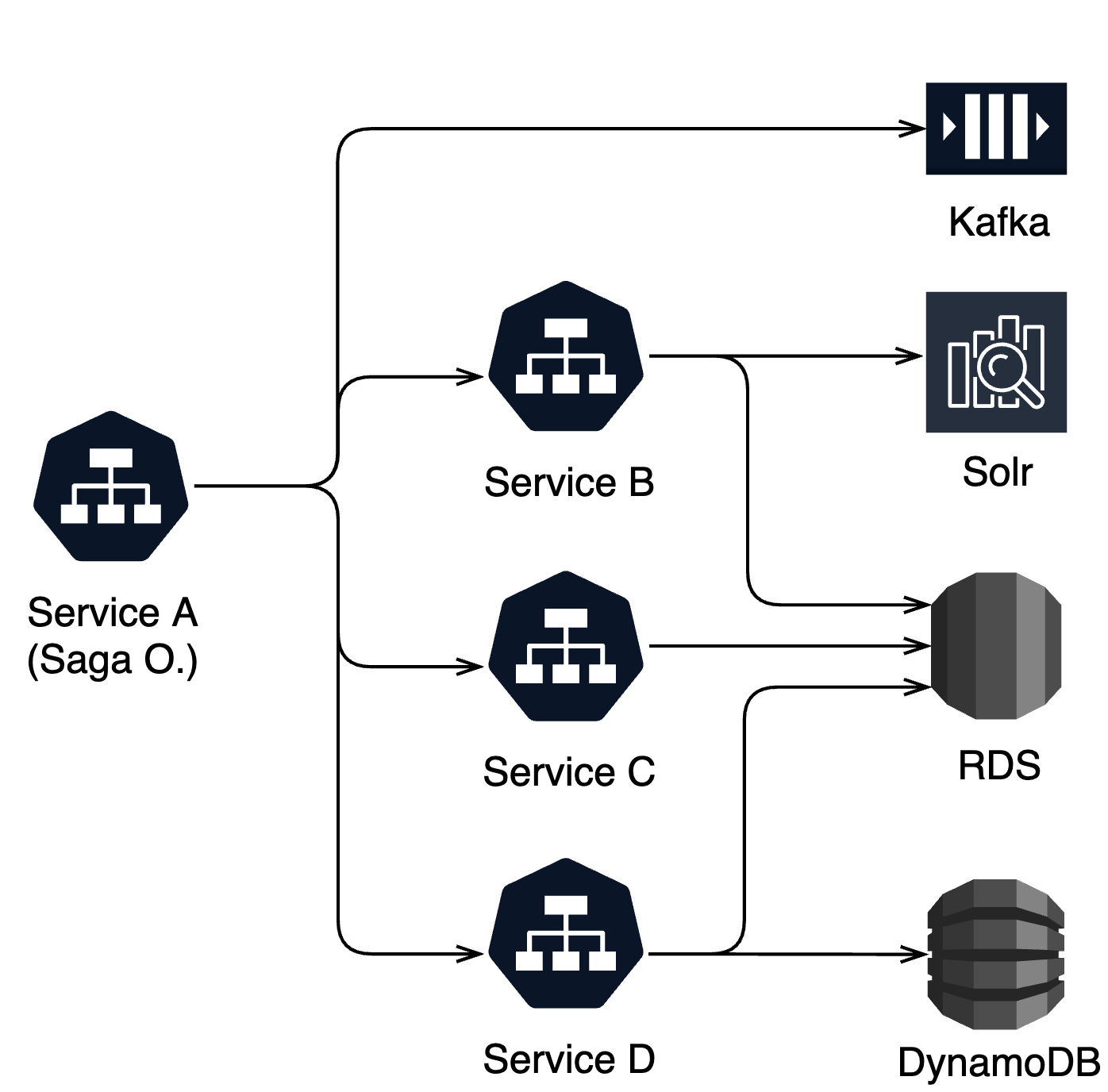
Service A is the orchestration organizer that drives Saga Orchestration’s processes, and Services B, C, and D are the three underlying services that use separate and heterogeneous databases.
Since Saga Orchestration is used instead of Choreography, only Service A is aware of the presence of distributed transactions and has dependencies on Kafka and Saga middleware, while the domain services B, C, and D only need to implement a few more compensation interfaces for A to call, without creating dependencies on Kafka and Saga.
Business Process
The flow of Service A from receiving a user request, triggering a distributed transaction, invoking each domain service in steps, and finally returning a response is shown in the figure.
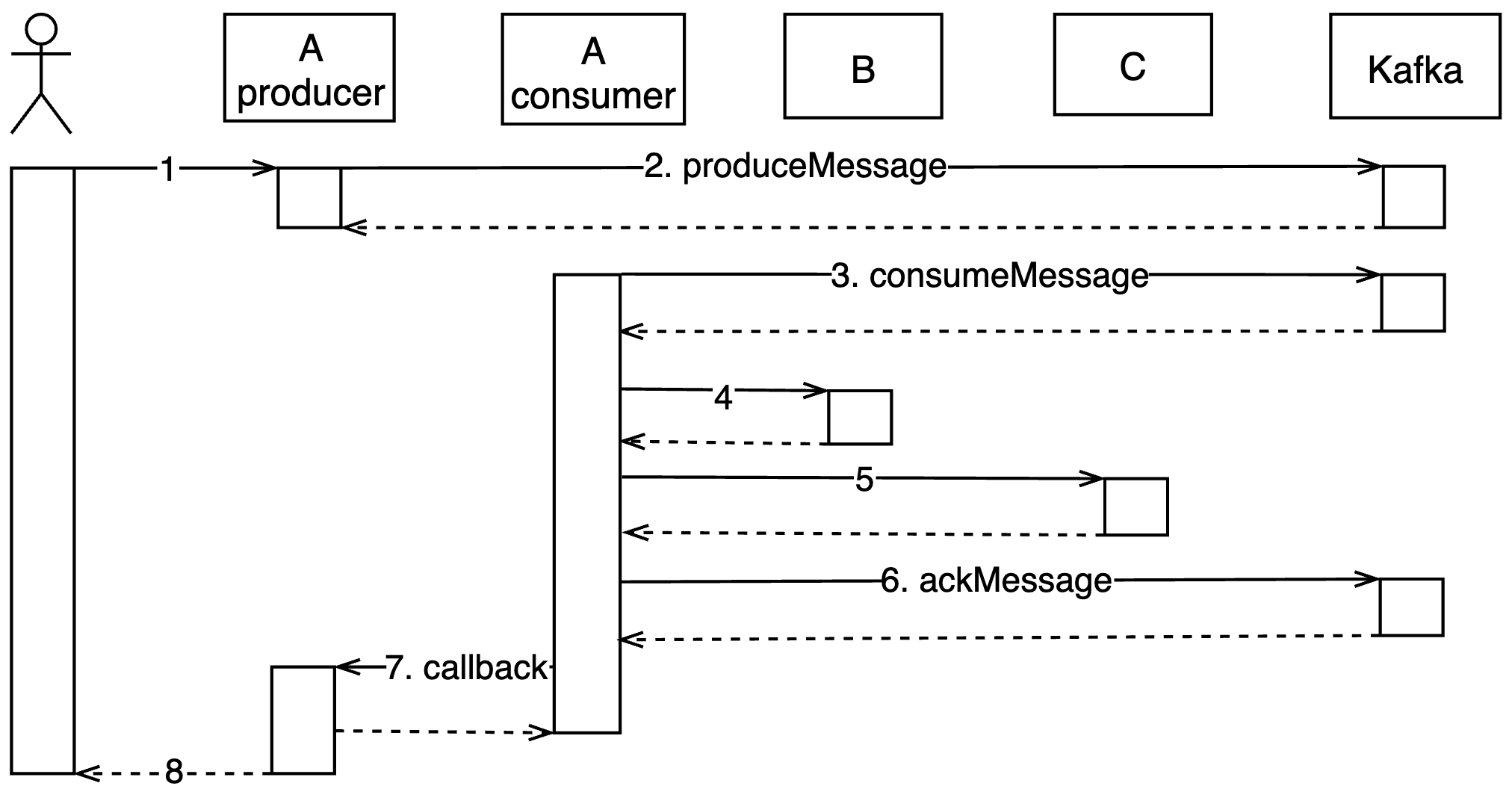
Step details:
- 1-2: After receiving a user request, a node of Service A first assumes the role of producer, wrapping the user request and callback address into a message and sending it to Kafka, and then the processing unit handling the user request blocks and waits.
- 3-5: A consumer in a node of the same service A receives a message from Kafka and starts driving the Saga Orchestration process, invoking the interfaces of services B and C in the order and logic defined by the business.
- 6-7: At the end of the Saga process, the consumer sends an acknowledgement of consumption progress (ackMessage, i.e., updates the consumer group offset) to Kafka, and then sends the result (success or failure, what changes were made) to the producer via an RPC callback address.
- 8: After receiving the data from the callback address, the producer finds the corresponding user request processing unit, unblocks it, and finally encapsulates the result into a user response.
Distributed Transactions Based on Saga and Kafka in Practice
After clarifying the design scheme of the distributed transaction system, this section describes some problems and attempts to solve them during testing and live operation.
Improvements to Kafka’s Parallel Consumption Model
The message data on Kafka is divided into topic and partition hierarchies, with topic, partition, and offset uniquely identifying a message. partition is the hierarchy responsible for ensuring message order. Kafka also supports multiple consumption of a message by different “services” (called multicast or fanout), and to distinguish between different “services”, introduces the concept of consumer groups, where a consumer group shares a consumption schedule on a partition (consumer group offset) on a partition. To ensure the order of message delivery, the data on a partition is available to at most one consumer at the same time and in the same consumer group.
This incurs some practical issues for Kafka users:
- Overestimation of partitions leads to wasted resources: the number of partitions on a given topic can only increase, not decrease, in order not to lose messages. This requires a topic to estimate its production and consumption capacity before going live, and then deploy it with an upper limit of production capacity and a lower limit of consumption capacity, and then set an upper limit of the number of partitions. If the production capacity of the topic is found to be higher than the consumption capacity, the partition must be expanded first, and then the consumption capacity must be increased (the most direct way is to increase the number of consumers). On the contrary, if the production capacity on the topic is found to be lower than the consumption capacity (either because the production rate of messages is lower than expected or fluctuates significantly, or because the consumption capacity of individual consumers has been increased through optimization), the number of partitions cannot be scaled back, resulting in a waste of Kafka’s resources. The reality is that the number of partitions is often overestimated and the processing power of the kafka topic is often wasted. That’s why business development engineers design various reuse mechanisms for topics and partitions.
- Partitioning is not sufficient to distinguish between messages that need to be consumed serially and those that can be consumed in parallel: Kafka’s default message partitioning strategy is to assign messages to a specific partition by computing hash values for their key fields, but it is possible that a group of consumers may not need to consume all messages on a partition serially. For example, if a service believes that messages A, B and C are all partitioned into partition 0, but only A and C have a sequential relationship (e.g., the same data is updated), B can be consumed in parallel with A and C. If there is a mechanism that allows the business to define which messages need to be consumed serially and the rest can be consumed in parallel, it can improve the consumption parallelism and processing power without changing the number of partitions, and reduce the dependence of code on the number of partitions.
To address the above two issues, distributed transactions make some improvements to the consumption part of Kafka: without violating ACID transactionality, a partition (partition) is repartitioned within a consumer process based on a subpartition ID (hereinafter referred to as id) and TxType, and messages from the same subpartition are consumed serially, while messages from different subpartitions are consumed in parallel. The messages of the same sub-partition are consumed serially and the messages of different sub-partitions are consumed parallel. As shown in the figure.
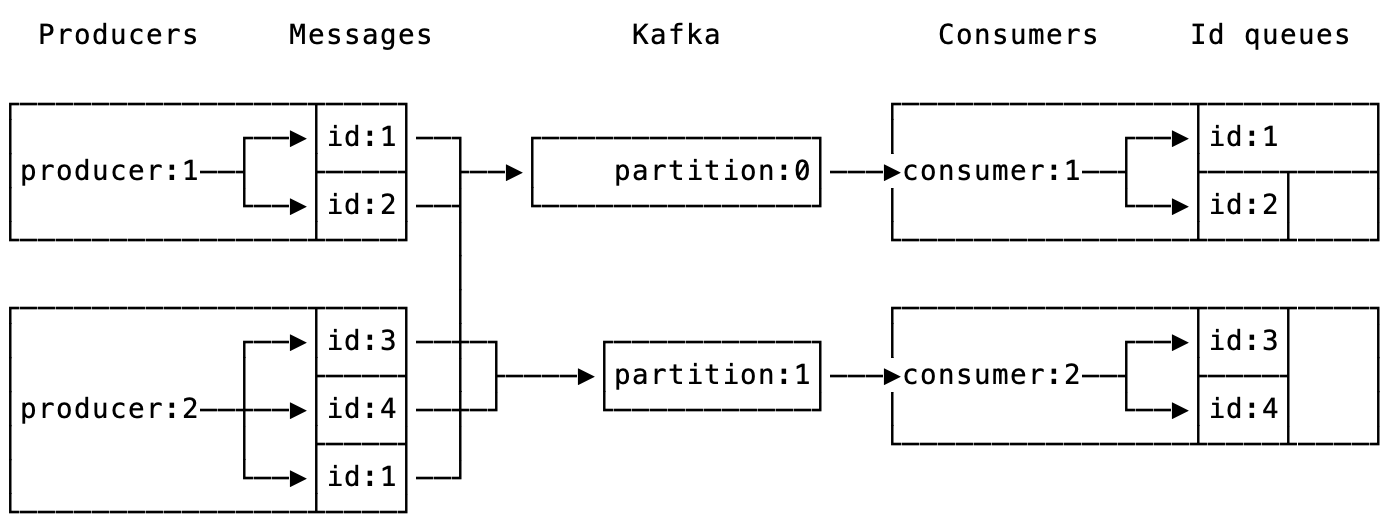
- The message id is utilized as the value of the Key field of the Kafka message by default, and the product engineer is allowed to customize the id of the message, but the value’s differentiation effect cannot be less than that of the Topic + Partition of the message.
- After the consumer process receives the message, the distributed transaction framework will first parse the metadata of the message to get the TxType and id of the message.
- The message is then repartitioned by “TxType + id” and automatically allocated and sent by the framework to a memory queue and processing unit for actual consumption by the business code.
- Messages with different “TxType + id” are assigned to different memory queues/processing units, which do not block each other and execute in parallel (or concurrently), and the degree of parallelism (concurrency) can be adjusted on the fly.
- As partitions are subdivided, the consumption progress defined on consumption groups and partitions requires an additional aggregation step to ensure that messages before a given offset are processed by the time Kafka sends an ack.
- The maximum length and maximum parallelism of memory queues/processing units can be configured and resources are reclaimed after a period of idleness to avoid memory buildup.
Deployment details
- Released as a code base: Instead of introducing standalone services, Saga and Kafka-related logic is extracted into a public code base that is released on a version-by-release basis, deployed and upgraded along with the services located in the combinatorial orchestrator layer.
- Producers and consumers coexist in the same process 1:1: for services that need to initiate and manage distributed transactions, each node starts a producer and a consumer, and with the help of an existing cluster deployment tool (Amazon EKS), all nodes of the service are guaranteed to be connected to each other and to Kafka. This deployment allows us to call back the producer node directly from the consumer node without introducing additional message buses or other data sharing mechanisms. Later, producers and consumers can be deployed on different services as needed, as long as their nodes are interconnected.
- Both Kafka and Go channel queueing modes are supported: when using Kafka queueing mode, the system conforms to the definition of ACID, while using Go channel queueing mode only guarantees A in ACID, not I and D. Go channel mode can be used during development and unit testing, and is generally used during service integration testing and online deployment. Kafka mode is generally used for service integration testing and online deployment. If the online Kafka service is not available as a whole, the service that initiates distributed transactions can be downgraded to Go channel mode.
- Shared Kafka topic and partition: Multiple services or processes can share Kafka topic and partition, use consumer groups to differentiate consumption progress, and use TxType to do event triage.
System availability analysis
The high availability of a distributed system relies on each service involved being robust enough. The following is a categorized exploration of the various services in a distributed transaction, describing the availability of the system when some of the service nodes fail.
- Producer failure: The producer is deployed with an organization/orchestrator service with node redundancy. If some nodes of the producer’s service fail, clients will see requests fail or time out for all transactions on that node that send queue messages and have not yet received callbacks, which can be successfully committed after retrying diversion to a normal node.
- Consumer failure: Consumers, like producers, are deployed with the organization/orchestrator service with node redundancy. If a consumer’s part of the node fails, the client will see the request timeout for all transactions on that node that have received a queue message and have not yet sent a callback and Kafka will mark the consumer offline after the configured consumer session timeout (default is 10 seconds, can be customized per consumer), and then load adjust the topic and partition to distribute as evenly as possible by some algorithm to the remaining consumers in the current consumer group. The load is then adjusted to the topic and partition, and distributed as evenly as possible to the remaining online members of the current consumer group according to a certain algorithm, and the load adjustment time is typically in the order of seconds. From the time the consumer’s node fails until the end of Kafka load tuning, the messages on the topic and partition that the failed consumer is responsible for cannot be processed during this time. Customers will see timeout errors for some requests. Retries with the same data will also fail during this time if the submitted data has a direct mapping to the partition that generated the queued message.
- domain service failure: A given distributed transaction will rely on multiple domain services, each deployed independently with redundant nodes. If some nodes of a basic service fail, the corresponding request of the distributed transaction will partially fail at the corresponding step, and the preceding steps will be executed in sequence to compensate for the interface. The customer sees a timeout or a failure message customized by the business, and a retry is likely to succeed. Businesses can introduce a service fusion mechanism to avoid message buildup.
- Message queue failure: Kafka itself has master-slave replication, node redundancy and data partitioning to achieve high availability, which is not discussed in depth here.
Production issues and handling
After the distributed transaction framework was released with the service, it ran online for a period of time and basically met the design expectations. There are some issues that have arisen during this period, which are listed below.
- Producer and consumer connectivity issues
A service using distributed transactions had a timeout on some data while other data returned normally, and client retries did not solve the issue. Analysis of the logs revealed that the messages were sent by producer and processed by consumer successfully, but the callback from the consumer to the producer failed. Further study of the logs revealed that the node where the consumer was located and the node where the producer were located were in different clusters that are of separate networks. Looking at the configuration, the same Kafka brokers, topics and consumer groups are configured for the same service in both clusters, and consumers in both clusters are connected to the same Kafka and are randomly assigned to process multiple partitions under the same topic.
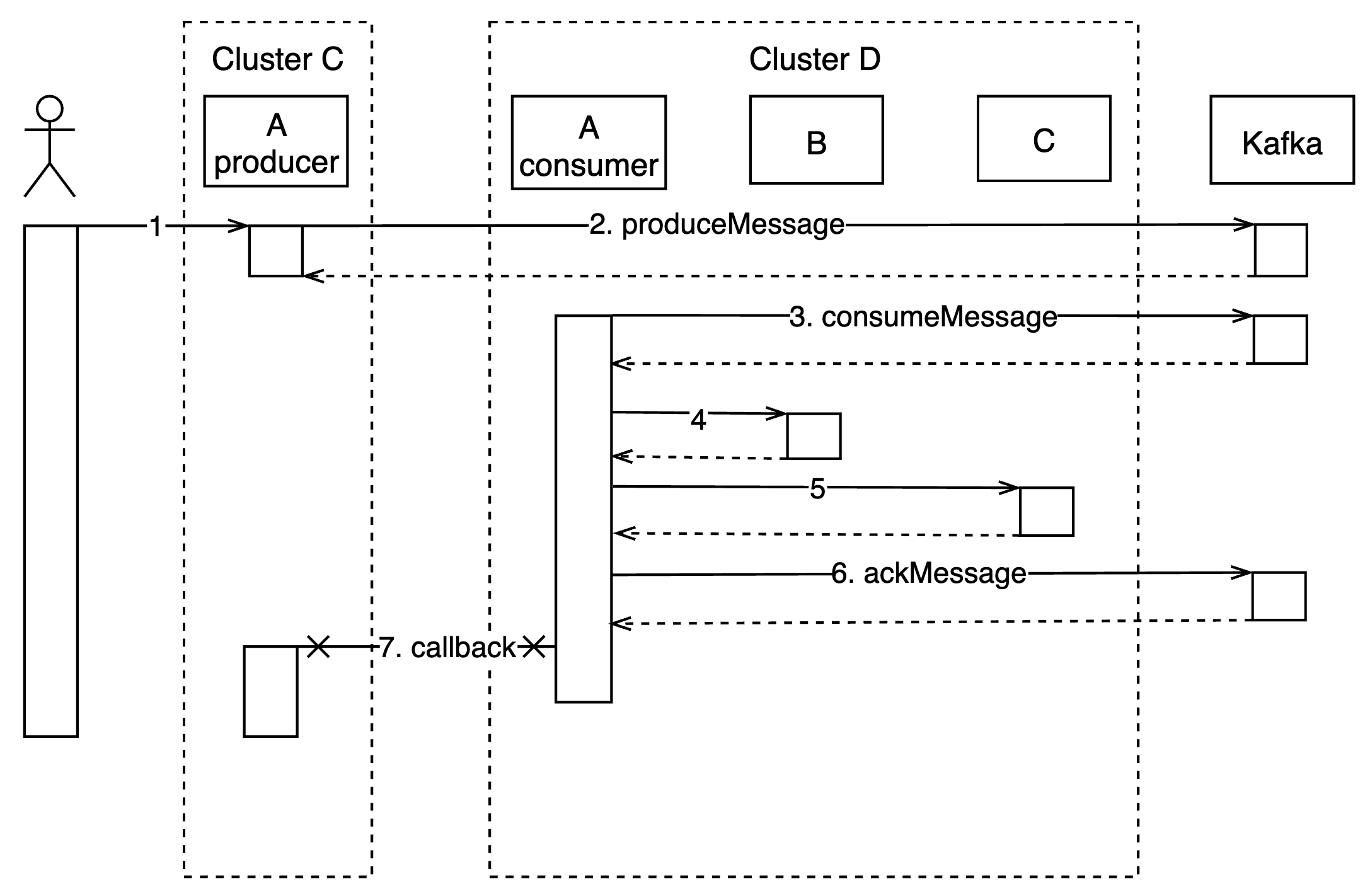
As shown in the figure, Service A (producer) in Cluster C and Service A (consumer) in Cluster D use the same Kafka configuration. Although their nodes are connected to Kafka, they are not directly connected to each other, so the callback in step 7 fails. The reason why some data timeouts and retries are invalid and others are fine is that the value of a particular data is mapped to a particular partition, so if the message producer and the consumer of the partition are not in the same cluster, the callback will fail; conversely, if they are in the same cluster, there is no problem. The solution is to modify the configuration so that services in different clusters use different Kafka.
- Problems with shared message queues
Service A has a business exception alarm about the consumer of a distributed transaction receiving a queue message of a type that does not meet expectations. By analyzing the logs and viewing the code, it is found that the message type belongs to Service B and the same message has already been processed by a consumer of Service B. Checking the configuration reveals that the distributed transactions of Service A and B use the same Kafka topic and are configured with different consumer groups to distinguish the progress of their respective consumption.
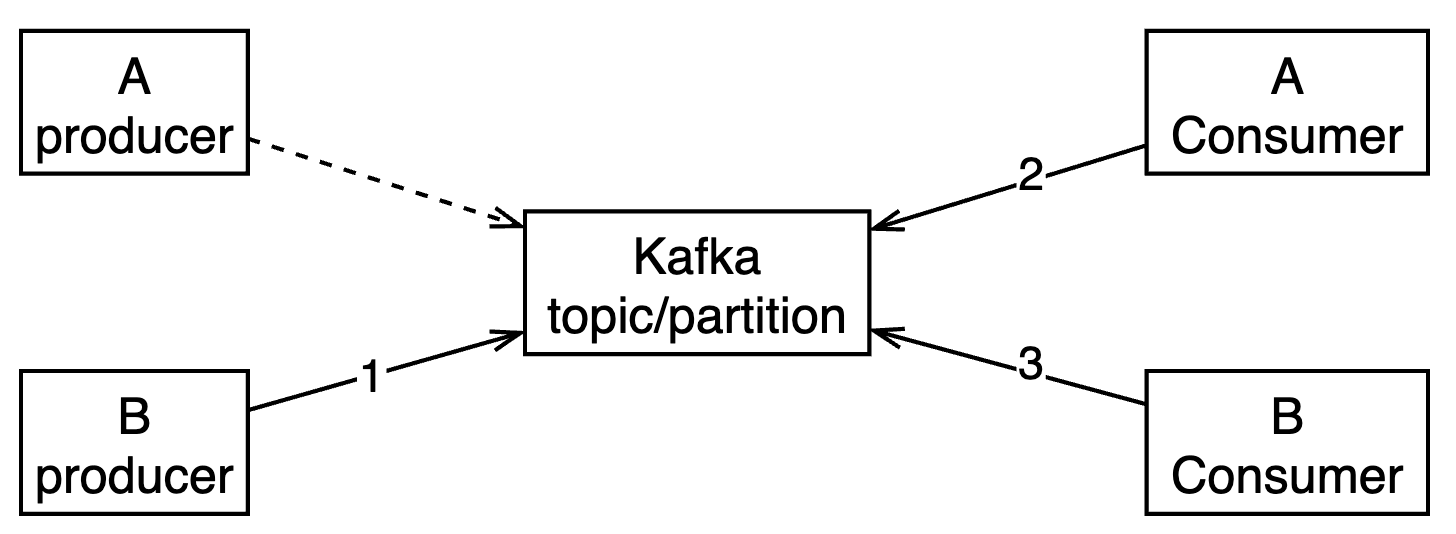
As shown in the figure, services A and B share the Kafka topic and partition, the exception message comes from service B’s producer (step 1), the exception alarm appears at A’s consumer (step 2), and B’s consumer also receives and processes the message (step 3), with steps 2 and 3 running in parallel. The producer of service A has no role in this exception. There are two ideas to solve this problem: either modify the configuration to remove Kafka topic sharing, or modify the logging to ignore unrecognized distributed transaction message types. Since the production capacity of Service A+B on this topic is less than the consumption capacity in the short term, removing the sharing would further waste Kafka resources, so the modified logging approach is used for now.
- System visibility improvements
One of the challenges of distributed systems is the difficulty in troubleshooting and isolating problems because the RPC call graphs is complex. The introduction of asynchronous queues for distributed transactions, where producers and consumers may be located on different nodes, requires a better solution about service visibility, especially request tracing.
For this reason, the distributed transaction system of FreeWheel’s core business system adopts the tracing system, which visualizes the flow of distributed transaction data across services and it helps engineers to pinpoint functional and performance problems, as shown in the figure.
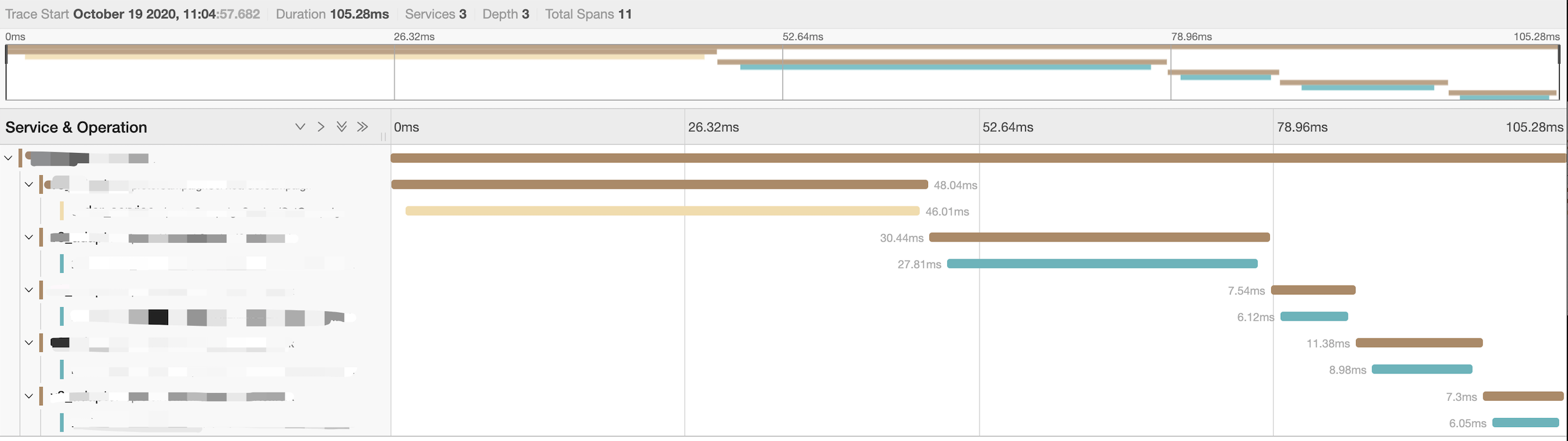
In addition, We can use Kafka’s multicast feature to browse and replay messages at any time using temporary consumer groups, which does not affect normal consumption of data.
- Loss of business exception details
A service using distributed transactions found that the customer had a steady 5xx error when committing specific data, and retries were ineffective.
After analyzing the logs, it was found that a basic service returned a 4xx error for that data (the business thought the input data was not valid), but after the exception capture and processing of the distributed transaction framework, the original details were lost and the exception was rewritten to a 5xx error before being sent to the customer.
The solution is to modify the exception handling mechanism of the framework to aggregate the raw exception information encountered at each step in the consumer process, package it into callback data and send it to the producer, allowing the business code to do further exception handling.
- The domain service creates duplicate data
Service A, which uses distributed transactions, finds that occasionally a request is successful, but multiple entries of the same data are created in the database managed by domain service B.
It was discovered through FreeWheel’s tracing system that Service A called B’s creation API and retried on timeouts, but both calls succeeded at Service B and the interface was not idempotent (i.e., the effect of multiple calls is equal to the effect of one call), resulting in the same data being created multiple times.
Similar problems arise frequently in microservices practice, and there are two ways to solve them.
-
One temporary solution is to let A and B share the timeout configuration; A passes its own timeout setting tA to B, and then B commits the data transactively according to a timeout tB that is shorter than tA (taking into account the network overhead between A and B).
-
Another way to solve the problem more generally is to implement idempotency in Service B’s interface (this can be done by setting unique keys in the database, creating data requests that require unique keys, and ignoring requests with conflicting keys).
Regardless of whether distributed transactions are used, the problem of duplicate data being requested multiple times by the client due to network retries is a pratical issue for every micro-service, and implementing interface idempotency is the preferred solution.
Chapter summary
This chapter discusses the concepts, technical approach and practices of distributed transactions based on our team’s experience and practice. We introduced a distributed transaction solution that supports heterogeneous databases with eventual consistency, and discussed the issues encountered after this solution went into production and the attempts to solving these issues.
As mentioned in the background section of this chapter, distributed transactions with eventual consistency guarantee are necessary for microservice systems, to bridge the divergence between the state of the business models and the state of the storage models, adapting for changing business requirements and continuous adjustment of service boundaries. However, the procurement of distributed transactions comes at the cost of adding dependency on queues and the maintenance effort of interfaces for compensating data, as well as higher requirements for idempotency of interfaces. If the descrepancy between logic and data could be eliminated at the root, i.e., by realigning the boundaries of the storage model with the business model, it would certainly be more straight-forward and resilient to encapsulate transactions to a single microservice and have the traditional ACID transactions supported by a relational database. Moreover, if for some business cases, the business models and storage models diverge but with less impact and frequency, we can also opt out to adopting distributed transactions, and collect exceptions through logging and monitoring system and handle the exceptions in batched task queues. After all, there’s no silver bullets for software development, and our systems (and ourselves too) must embrace change and move agile to stay relevant.